Power for a covariate-adjusted cluster trial
You run a trial where whole clinics — not individual patients — are randomised to a treatment or a control arm, and you measure blood pressure on every patient afterwards. Patients in the same clinic resemble each other, so their outcomes are correlated; ignoring that with plain OLS understates the uncertainty in the treatment effect. You also have a baseline blood pressure reading for each patient, and adjusting for it soaks up between-patient variability the same way an ANCOVA does. The model carries both: a random intercept per clinic for the clustering, and a continuous baseline covariate for the adjustment.
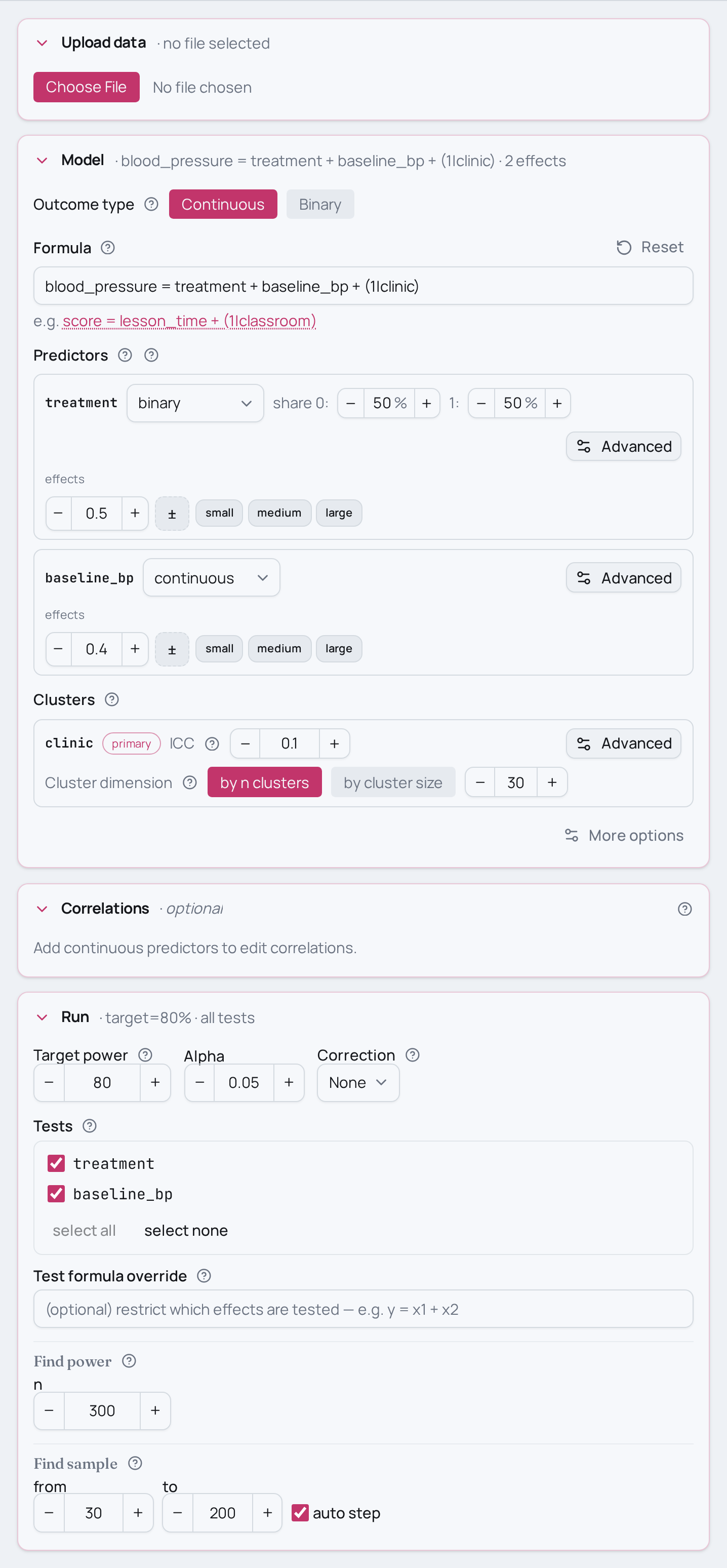
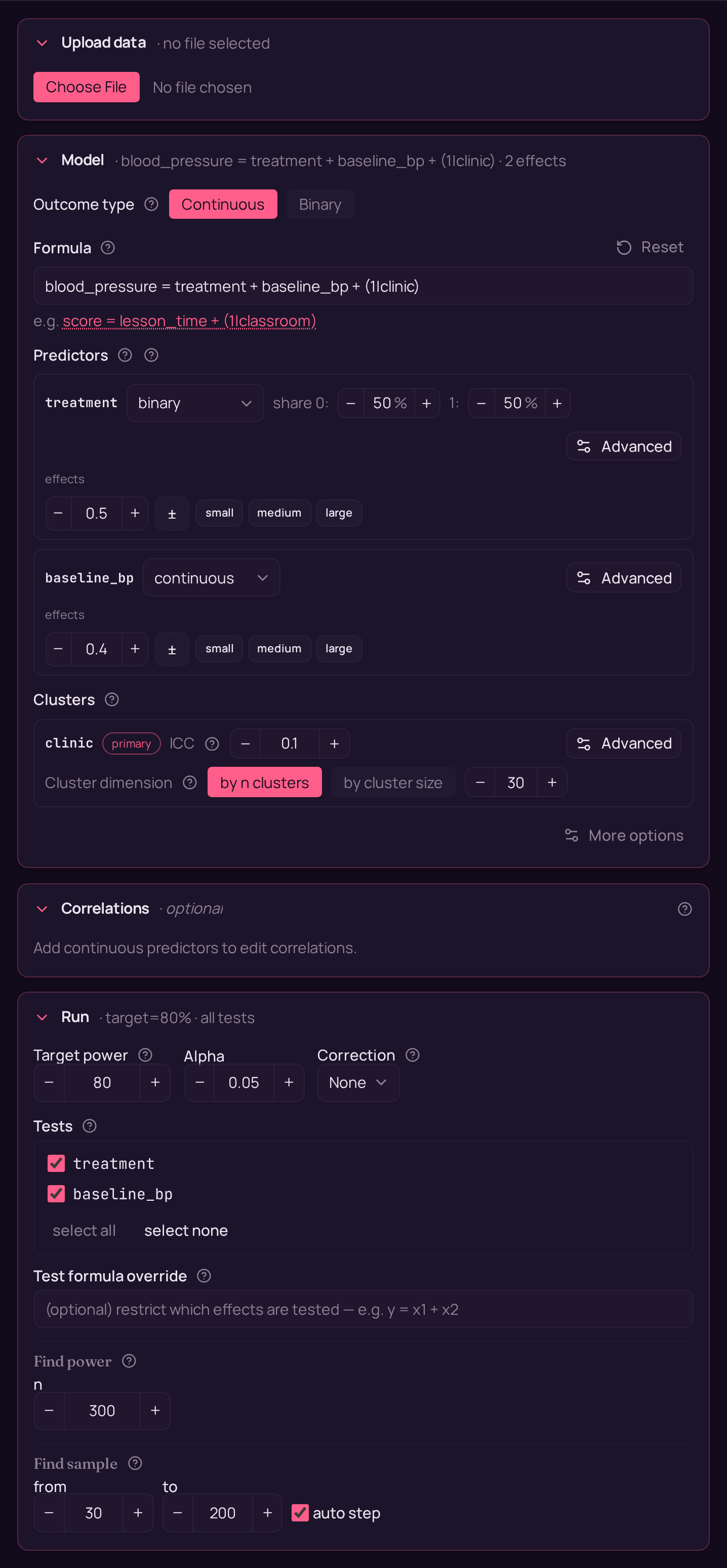
The model is blood_pressure = treatment + baseline_bp + (1|clinic) — a
baseline-adjusted treatment effect with a per-clinic random intercept, fit by
maximum likelihood (the lme family).
Variations
- No baseline measurement. Drop the
baseline_bpterm and analyseblood_pressure = treatment + (1|clinic)— the unadjusted cluster-randomised trial, which needs more N for the same power because nothing absorbs the between-patient noise. - A weaker covariate. Dial
baseline_bpdown to the 0.25 medium benchmark (or 0.10 small) when the baseline reading only loosely predicts the follow-up — the adjustment buys you less. - Stronger or weaker clustering. Push the ICC up toward 0.20 when clinics differ a lot, or down toward 0.05 when they barely differ; higher ICC costs power for a fixed number of patients per clinic.
- Fewer, larger clusters. Hold N fixed but set
n_clustersto 15 instead of 30 — twice as many patients per clinic. With cluster randomisation the number of clinics usually matters more for power than the patients within them. - More than two arms. Swap the binary
treatmentfor a 3-level factordose_level(e.g.dose_level[2],dose_level[3]); the design stays a baseline-adjusted cluster trial, now with a multi-level comparison. - Same design, other fields:
biomass ~ treatment + baseline_weight + (1|tank)— tanks randomised to treatment; baseline plant weight as a covariate (ecology).wage ~ training + experience_years + (1|sector)— sectors randomised; pre-programme experience as a covariate (social science).
Not this setup?
- Same cluster-randomised trial without the baseline covariate — the unadjusted random-intercept model.
- The non-clustered analogue — ANCOVA adjusting a group effect for a baseline covariate, with no random intercept.
- Cluster trial where the treatment effect varies across clusters — a random treatment slope instead of just adding a covariate.
If you'd rather have…
- The unadjusted cluster trial — same two-level cluster-randomised trial but without the baseline covariate — the unadjusted random-intercept model.
- The non-clustered analogue — ANCOVA adjusting a group effect for a baseline covariate (no random intercept).
- A random treatment slope — cluster RCT extended so the treatment effect varies across clusters (random treatment slope) instead of just adding a covariate.
- A binary-outcome cluster trial — a cluster-randomised trial with a binary outcome instead of continuous — the GLMM counterpart.
- A longitudinal trial — treatment-by-week interaction with a random intercept per patient, if your trial follows patients over time.
Copy-paste setup
from mcpower import MCPower
# Cluster-randomised trial, baseline-adjusted: clinics are assigned to
# treatment or control, patients are measured within clinics, and each patient
# has a baseline blood pressure reading. The (1|clinic) term adds a random
# intercept per clinic; family="lme" fits it by maximum likelihood (MLE estimator).
model = MCPower("blood_pressure = treatment + baseline_bp + (1|clinic)", family="lme")
# Expected effect sizes (standardised benchmark scale):
# treatment=0.50 -> a medium binary (between-arm) effect on blood pressure.
# baseline_bp=0.40 -> the baseline reading is a strong continuous covariate.
model.set_effects("treatment=0.50, baseline_bp=0.40")
# Treatment is randomised at the clinic level (0=control, 1=treatment);
# baseline_bp stays continuous by default.
model.set_variable_type("treatment=binary")
# Describe the clustering: ICC=0.10 (10% of outcome variance is between clinics)
# across 30 clinics. At N=300 that is 10 patients per clinic.
model.set_cluster("clinic", ICC=0.10, n_clusters=30)
# Power at N=300 for the baseline-adjusted treatment effect (mixed defaults:
# 800 sims, alpha=0.05, seed=2137). The omnibus test is not reported for mixed
# models; target the coefficient directly.
model.find_power(sample_size=300, target_test="treatment")
suppressMessages(library(mcpower))
# Cluster-randomised trial, baseline-adjusted: clinics are assigned to
# treatment or control, patients are measured within clinics, and each patient
# has a baseline blood pressure reading. The (1|clinic) term adds a random
# intercept per clinic; family = "lme" fits it by maximum likelihood (MLE estimator).
model <- MCPower$new("blood_pressure ~ treatment + baseline_bp + (1|clinic)", family = "lme")
# Expected effect sizes (standardised benchmark scale):
# treatment=0.50 -> a medium binary (between-arm) effect on blood pressure.
# baseline_bp=0.40 -> the baseline reading is a strong continuous covariate.
model$set_effects("treatment=0.50, baseline_bp=0.40")
# Treatment is randomised at the clinic level (0=control, 1=treatment);
# baseline_bp stays continuous by default.
model$set_variable_type("treatment=binary")
# Describe the clustering: ICC=0.10 (10% of outcome variance is between clinics)
# across 30 clinics. At N=300 that is 10 patients per clinic.
model$set_cluster("clinic", ICC = 0.10, n_clusters = 30)
# Power at N=300 for the baseline-adjusted treatment effect (mixed defaults:
# 800 sims, alpha=0.05, seed=2137). The omnibus test is not reported for mixed
# models; target the coefficient directly.
invisible(model$find_power(sample_size = 300, target_test = "treatment"))