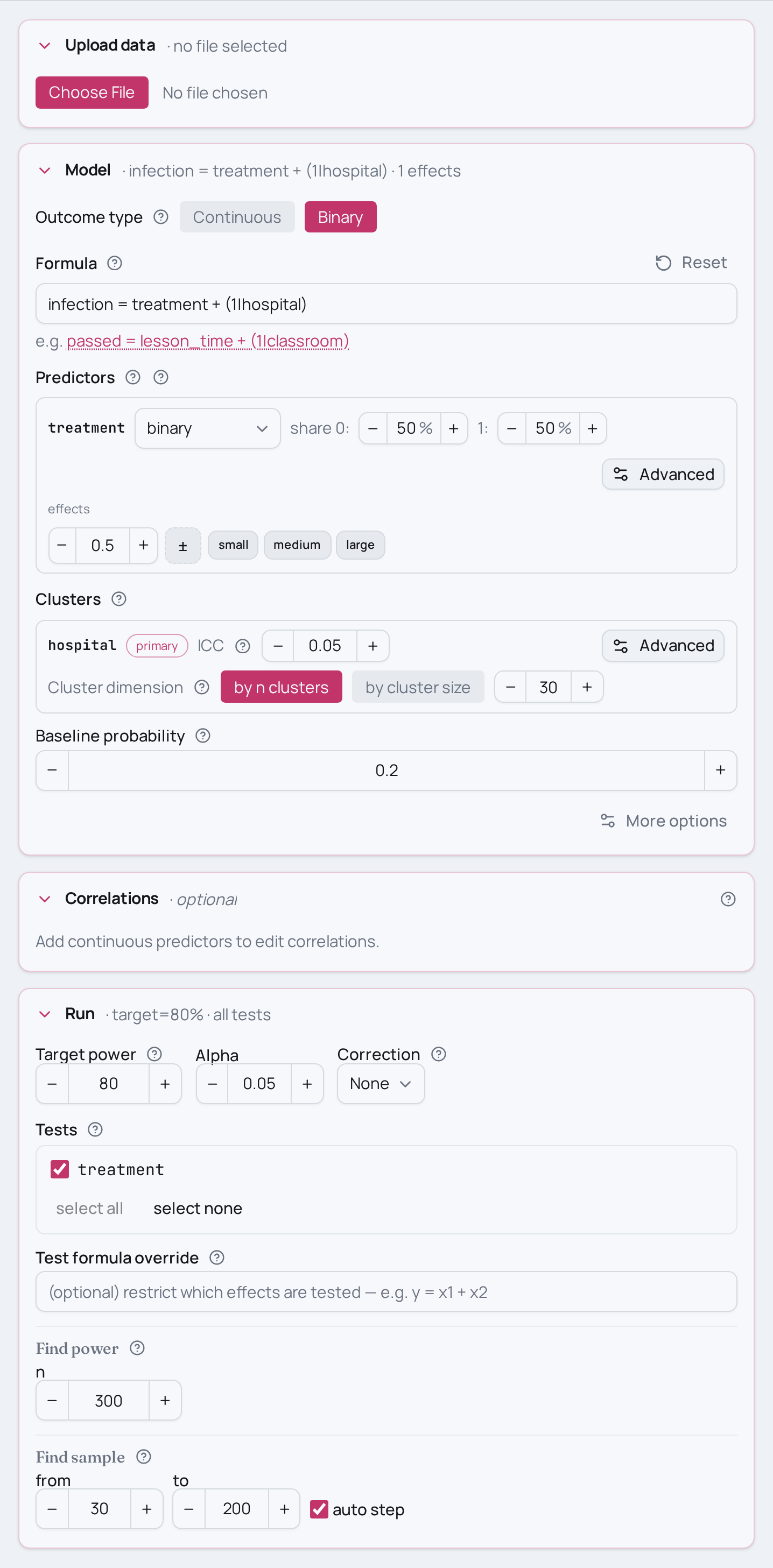
Power analysis for a cluster-randomised binary trial
You ran a trial where whole hospitals were randomised to control vs treatment,
and the outcome is whether each patient developed an infection (yes/no). Every
patient inside a hospital shares its assignment, so the responses within a
hospital are correlated and a plain logistic regression would overstate your
power. This is the cluster-randomised binary trial, written as a clustered
logistic model: infection ~ treatment + (1 | hospital).
Variations
- Smaller or larger gap. The effect is on the binary benchmark scale —
swap
treatment=0.50(medium) fortreatment=0.20(small) ortreatment=0.80(large) to see how the expected separation between the two infection rates moves power. - Different control infection rate. The baseline probability anchors how
common infection is in the control arm — move
set_baseline_probability(0.20)to a rarer (0.05) or more common (0.50) base rate; rare events cost power for the same total N. - More or fewer hospitals. With clustered data the number of clusters drives
power more than the headcount does — raise
n_clusters=30ton_clusters=60(more, smaller hospitals) and watch power climb faster than adding patients to existing hospitals would. - Stronger clustering. The ICC sets how alike patients in a hospital are —
bump
ICC=0.05toICC=0.10to model tighter within-hospital correlation; higher ICC erodes the power of a cluster-randomised design for the same N. - Solve for N instead. Replace
find_power(sample_size=300, …)withfind_sample_size(target_test="treatment", from_size=100, to_size=600, by=25)to get the minimum N that reaches 80% power. - Same design, other fields
- Ecology:
germinated ~ treatment + (1|tank)— seedling germination (yes/no) randomised at the tank level across 30 tanks, one pesticide treatment per tank. - Social science:
voted ~ treatment + (1|region)— voter turnout (yes/no) in a get-out-the-vote cluster RCT where regions are the clusters.
- Ecology:
Not this setup?
- A within-subject time predictor instead of cluster treatment
- The same cluster-randomised design on a continuous outcome
- The same two-group binary comparison without clustering
If you'd rather have…
- A continuous outcome instead of a binary event — same cluster-randomised design (random intercept per cluster) but for a continuous outcome instead of binary.
- No clustering at all — same binary two-group treatment comparison, but without clustering (plain logistic regression).
- A longitudinal within-subject predictor — binary GLMM with a random intercept, but adds a within-subject time predictor (longitudinal) rather than between-cluster treatment.
- A group-by-time difference-in-differences design — binary GLMM extending to a group-by-time difference-in-differences design with a random intercept.
- A baseline covariate added to the cluster RCT — cluster RCT with a baseline covariate adjustment — add a covariate to the cluster-randomised design (continuous outcome version).
Copy-paste setup
from mcpower import MCPower
# Cluster-randomised trial on a binary (infection / no-infection) outcome:
# hospitals are randomised to control vs treatment, and every patient in a
# hospital shares its assignment. The (1|hospital) term adds a random intercept
# per hospital; family="logit" makes this a clustered logistic model (binary GLMM).
model = MCPower("infection = treatment + (1|hospital)", family="logit")
# treatment is a binary two-level predictor (0 = control, 1 = treatment),
# assigned at the hospital level rather than per patient.
model.set_variable_type("treatment=binary")
# Expected treatment effect on the binary benchmark scale: 0.50 = a medium gap.
model.set_effects("treatment=0.50")
# Infection rate in the control arm (logit family needs a baseline probability).
model.set_baseline_probability(0.20)
# Describe the clustering: ICC=0.05 (5% of variance is between hospitals) across
# 30 hospitals. At N=300 that is 10 patients per hospital.
model.set_cluster("hospital", ICC=0.05, n_clusters=30)
# Power at N=300 for the fixed effect of treatment (mixed defaults: 800 sims,
# alpha=0.05, seed=2137). The omnibus test is not reported for mixed models;
# target the coefficient directly.
model.find_power(sample_size=300, target_test="treatment")
suppressMessages(library(mcpower))
# Cluster-randomised trial on a binary (infection / no-infection) outcome:
# hospitals are randomised to control vs treatment, and every patient in a
# hospital shares its assignment. The (1|hospital) term adds a random intercept
# per hospital; family = "logit" makes this a clustered logistic model (binary GLMM).
model <- MCPower$new("infection ~ treatment + (1|hospital)", family = "logit")
# treatment is a binary two-level predictor (0 = control, 1 = treatment),
# assigned at the hospital level rather than per patient.
model$set_variable_type("treatment=binary")
# Expected treatment effect on the binary benchmark scale: 0.50 = a medium gap.
model$set_effects("treatment=0.50")
# Infection rate in the control arm (logit family needs a baseline probability).
model$set_baseline_probability(0.20)
# Describe the clustering: ICC=0.05 (5% of variance is between hospitals) across
# 30 hospitals. At N=300 that is 10 patients per hospital.
model$set_cluster("hospital", ICC = 0.05, n_clusters = 30)
# Power at N=300 for the fixed effect of treatment (mixed defaults: 800 sims,
# alpha=0.05, seed=2137). The omnibus test is not reported for mixed models;
# target the coefficient directly.
invisible(model$find_power(sample_size = 300, target_test = "treatment"))