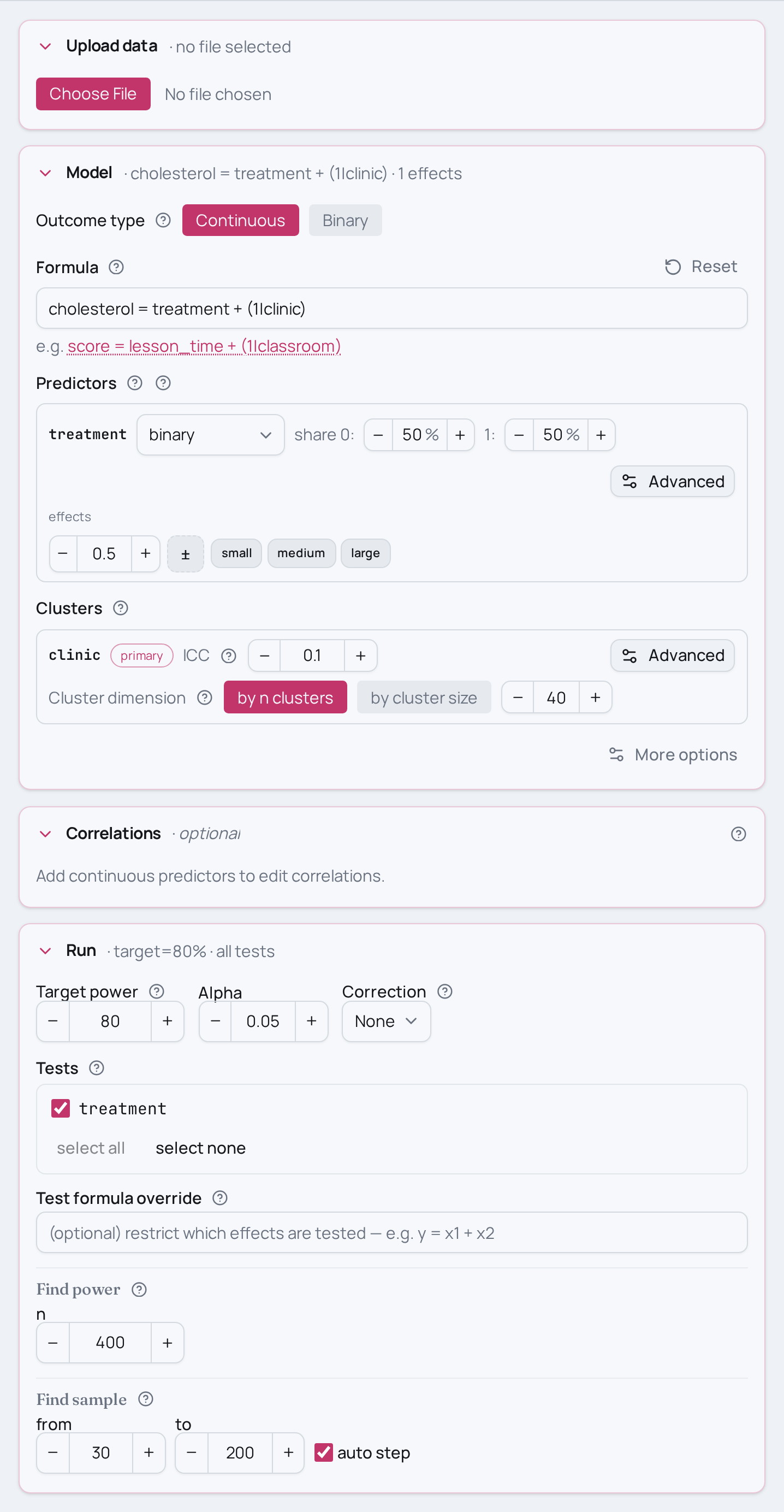
Power for a cluster-randomized trial
You ran a trial where whole clinics were randomized to a treatment, and you
measured cholesterol on the patients inside them. Patients in the same clinic
resemble each other, so a plain regression would treat correlated observations as
if they were independent. A random intercept per clinic absorbs that
between-clinic variation: cholesterol ~ treatment + (1|clinic), fit by maximum
likelihood (the MLE estimator for family="lme").
Variations
- Smaller or larger treatment effect. The effect is on the binary benchmark
scale — swap
treatment=0.50(medium) fortreatment=0.20(small) ortreatment=0.80(large) to see how the expected group gap moves power. - More or stronger clustering. Move
set_cluster("clinic", ICC=0.10, …)to a higher ICC (e.g.0.20) when clinics differ more from each other — stronger clustering costs power for the same total N. The ICC is the within-clinic correlation that survives after the treatment is accounted for. - Trade clusters against cluster size. Keep N fixed but swap
n_clusters=40forn_clusters=20(now 20 patients per clinic) — for a cluster-randomized design more clinics usually buys more power than more patients per clinic. - Add a covariate. Append a pre-treatment continuous control (e.g.
cholesterol ~ treatment + baseline_bp + (1|clinic),baseline_bp=0.25) to adjust the treatment estimate and recover power. - Solve for N instead. Replace
find_power(sample_size=400, …)withfind_sample_size(target_test="treatment", from_size=120, to_size=600, by=40)to get the minimum N that reaches 80% power. - Same design, other fields:
biomass ~ treatment + (1|tank)— one tank per treatment arm; test whether plant biomass differs across tanks (ecology).wage ~ training + (1|sector)— one sector per arm; test whether a training programme shifts wages across sectors (social science).
Not this setup?
- Treatment effect with a continuous covariate adjustment
- The same cluster-randomized trial on a binary outcome
- Treatment compared across 3+ groups in clustered data
If you'd rather have…
- A treatment effect that varies across sites — let the treatment effect vary across clusters/sites (random treatment slope) instead of a single fixed effect.
- Repeated measures on patients — random intercept grouping units that are repeatedly measured (patients) rather than randomized clusters.
- The same contrast without clustering — estimate the same two-group treatment contrast without any clustering / random effect.
Copy-paste setup
from mcpower import MCPower
# Cluster-randomized trial: does the treatment lower cholesterol, once we
# account for patients in the same clinic being correlated? A random intercept
# per clinic soaks up that between-clinic variation.
model = MCPower("cholesterol = treatment + (1|clinic)", family="lme")
# treatment is a binary two-level predictor (0 = control, 1 = treatment).
model.set_variable_type("treatment=binary")
# Expected effect on the binary benchmark scale: 0.50 = a medium treatment gap.
model.set_effects("treatment=0.50")
# Clustering: ICC=0.10 (10% of variance is between-clinic) across 40 clinics.
# At N=400 that is 10 patients per clinic.
model.set_cluster("clinic", ICC=0.10, n_clusters=40)
model.find_power(sample_size=400, target_test="treatment")
suppressMessages(library(mcpower))
# Cluster-randomized trial: does the treatment lower cholesterol, once we
# account for patients in the same clinic being correlated? A random intercept
# per clinic soaks up that between-clinic variation.
model <- MCPower$new("cholesterol ~ treatment + (1|clinic)", family = "lme")
# treatment is a binary two-level predictor (0 = control, 1 = treatment).
model$set_variable_type("treatment=binary")
# Expected effect on the binary benchmark scale: 0.50 = a medium treatment gap.
model$set_effects("treatment=0.50")
# Clustering: ICC=0.10 (10% of variance is between-clinic) across 40 clinics.
# At N=400 that is 10 patients per clinic.
model$set_cluster("clinic", ICC = 0.10, n_clusters = 40)
invisible(model$find_power(sample_size = 400, target_test = "treatment"))