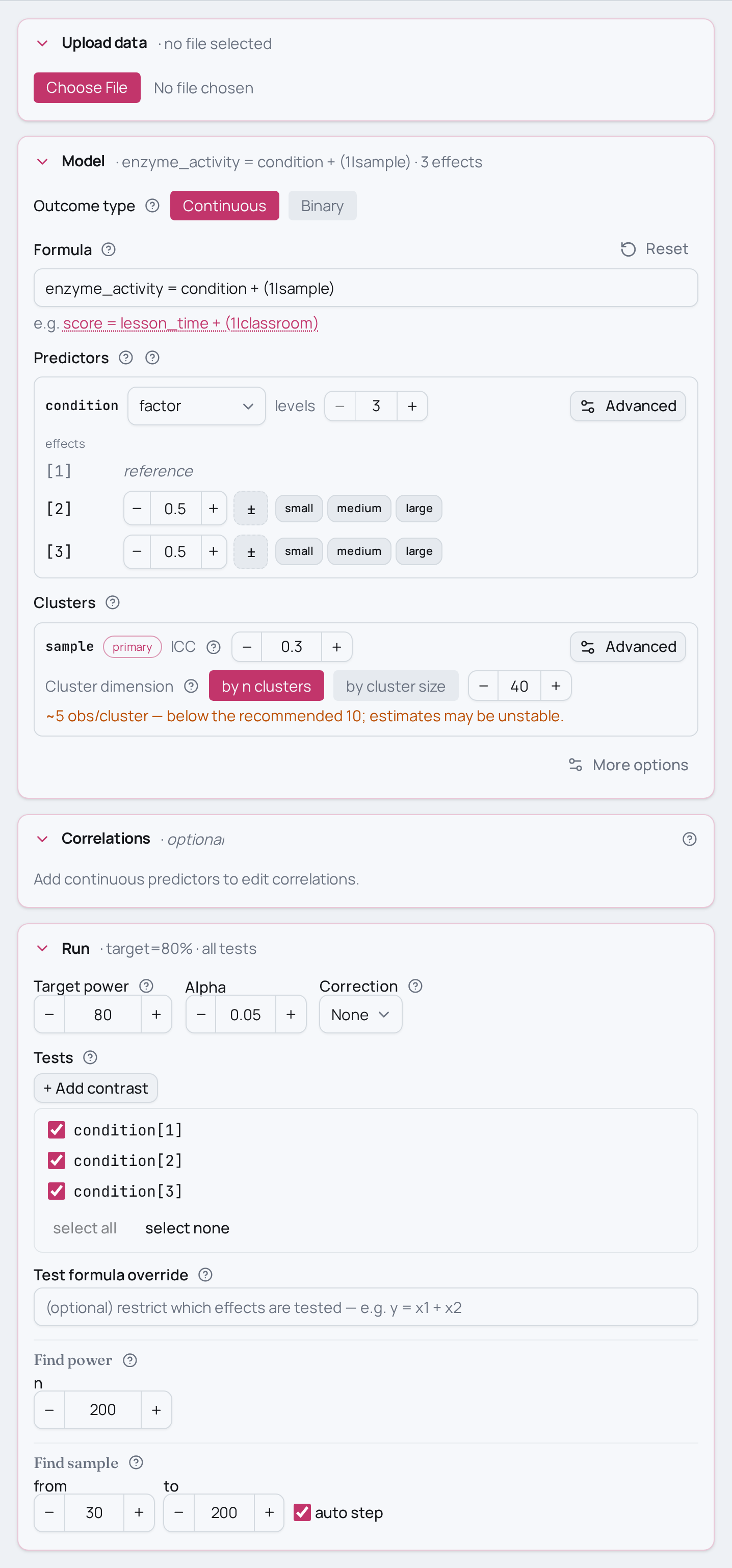
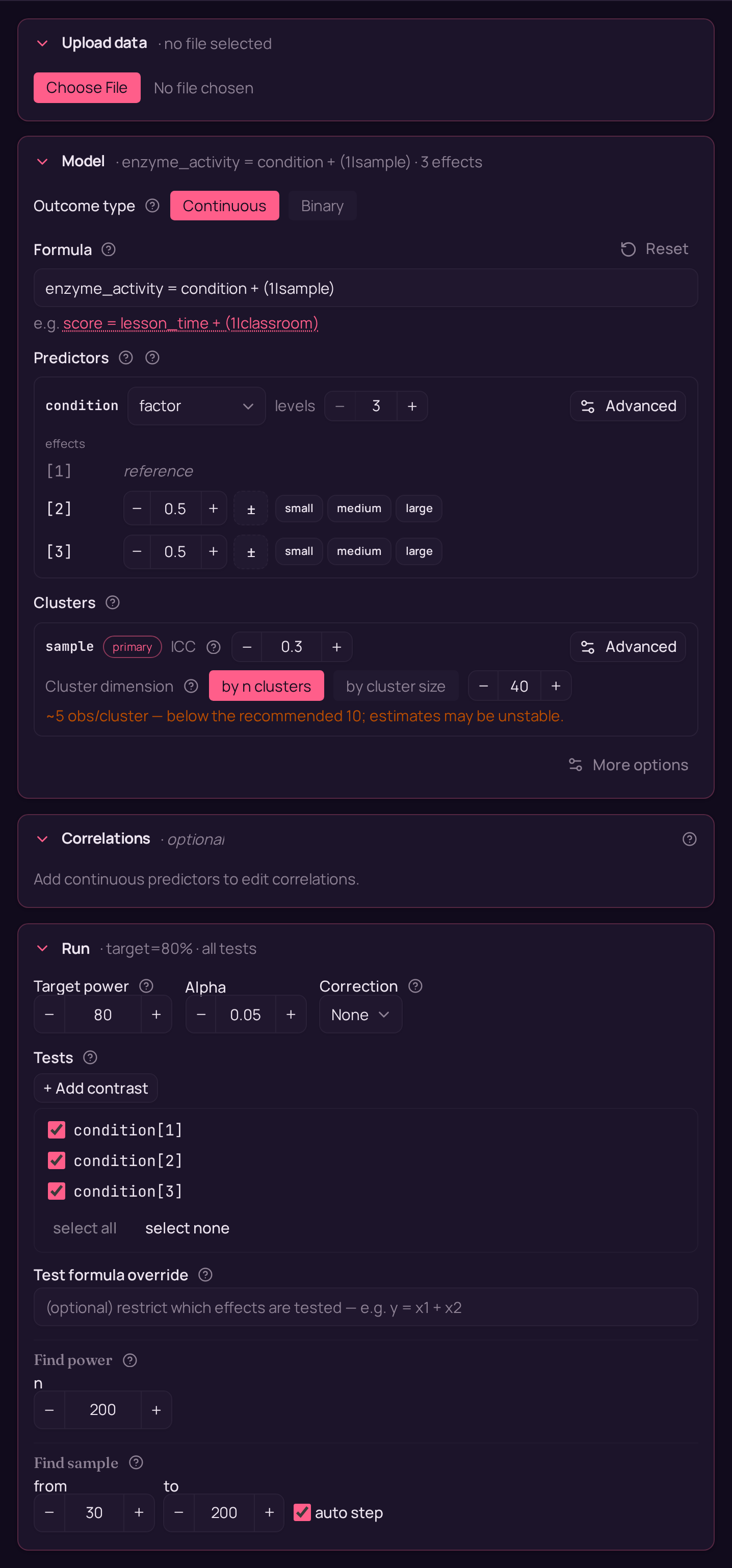
Power for a within-subjects one-way design
You ran a within-subjects biochemistry experiment — every sample was assayed under each of three (or more) conditions — and recorded enzyme activity as a continuous outcome. Because the same samples supply every condition, their readings are correlated; a plain regression that ignored that would mis-state the precision. You want the power to detect that the conditions differ, read off the individual condition coefficients rather than a single omnibus verdict.
As an MCPower model this is enzyme_activity = condition + (1|sample), where
condition is a 3-level factor and (1|sample) is a random intercept per sample.
The model is fit by maximum likelihood (the MLE estimator); the factor expands into
two dummy contrasts, each comparing a non-reference condition against the reference,
and power is reported for each contrast separately.
Variations
- More than three conditions. Bump the factor to its real count —
condition=(factor,4)for four conditions. Each extra level adds one more dummy contrast (and one more row of power) against the same reference. - Unequal expected effects per condition. A single
condition=0.5puts the same shift on every non-reference condition. To say one condition is stronger, set the level effects apart rather than sharing one number across the factor. - Stronger or weaker within-sample correlation. ICC=0.30 says 30% of the
variance sits between samples. Raise it (more consistent samples,
ICC=0.50) or lower it to match your pilot — higher ICC lifts power on a within-subject factor. - Search for the N instead of fixing it. Swap the
find_powercall forfind_sample_size(target_test="condition", from_size=80, to_size=400, by=20)to get the smallest N that reaches target power on both contrasts. - Same design, other fields:
systolic_bp ~ phase + (1|patient)— one patient measured at several clinical phases; test whether BP differs across phases (clinical).well_being ~ period + (1|individual)— one person assessed at several survey periods; test whether well-being differs across periods (social science).
Not this setup?
- A two-level pre/post phase factor instead of 3+ conditions
- Random intercept by clinic (between-cluster) instead of repeated measures
- A between-subjects treatment arm crossed with the within-subject factor
If you'd rather have…
- lmm/lmm-01 — Same random-intercept-per-patient repeated-measures structure, but the within-subject predictor is a two-level phase factor rather than a 3+-level condition factor.
- lmm/lmm-02 — Adds a between-subjects treatment arm crossed with the within-subject factor (treatment x week), if your repeated design also has a group factor.
- lmm/lmm-05 — Same
outcome = predictor + (1|grouping)random-intercept form, but clustering is by clinic (between-cluster design) instead of repeated measures within sample. - anova/anova-01 — One-way omnibus test across 3+ groups if your conditions are between-subjects (independent groups) rather than repeated within each sample.
- ols/ols-12 — A 3+-level categorical predictor as ordinary regression if there is no repeated-measures / clustering structure to model.
Copy-paste setup
from mcpower import MCPower
# Repeated-measures biochemistry experiment: every sample is assayed under each
# of several conditions, so the condition factor varies *within* sample. The
# (1|sample) term adds a random intercept per sample to soak up the
# between-sample correlation; family="lme" fits it by maximum likelihood
# (MLE estimator).
model = MCPower("enzyme_activity = condition + (1|sample)", family="lme")
# condition is a categorical predictor with 3 levels -> 2 dummy contrasts, each
# comparing a non-reference condition against the reference.
model.set_variable_type("condition=(factor,3)")
# Standardised effects on the factor benchmark scale (0.20 / 0.50 / 0.80):
# each non-reference condition shifts enzyme activity by a medium amount vs reference.
# A factor expands into one dummy per non-reference level, so effects are named
# per dummy (condition[2], condition[3]) — the bare factor name is not an effect.
model.set_effects("condition[2]=0.5, condition[3]=0.5")
# Describe the clustering: ICC=0.30 (30% of variance is between samples)
# across 40 samples. At N=200 that is 5 measurements per sample — the
# minimum the engine requires for reliable mixed-model estimation.
model.set_cluster("sample", ICC=0.30, n_clusters=40)
# Power at N=200 for both dummy contrasts (mixed defaults: 800 sims, alpha=0.05,
# seed=2137). The omnibus test is not reported for mixed models; target the
# condition dummy coefficients directly (the bare factor name is not a test).
model.find_power(sample_size=200, target_test="condition[2], condition[3]")
suppressMessages(library(mcpower))
# Repeated-measures biochemistry experiment: every sample is assayed under each
# of several conditions, so the condition factor varies *within* sample. The
# (1|sample) term adds a random intercept per sample to soak up the
# between-sample correlation; family = "lme" fits it by maximum likelihood
# (MLE estimator).
model <- MCPower$new("enzyme_activity ~ condition + (1|sample)", family = "lme")
# condition is a categorical predictor with 3 levels -> 2 dummy contrasts, each
# comparing a non-reference condition against the reference.
model$set_variable_type("condition=(factor,3)")
# Standardised effects on the factor benchmark scale (0.20 / 0.50 / 0.80):
# each non-reference condition shifts enzyme activity by a medium amount vs reference.
# A factor expands into one dummy per non-reference level, so effects are named
# per dummy (condition[2], condition[3]) — the bare factor name is not an effect.
model$set_effects("condition[2]=0.5, condition[3]=0.5")
# Describe the clustering: ICC=0.30 (30% of variance is between samples)
# across 40 samples. At N=200 that is 5 measurements per sample — the
# minimum the engine requires for reliable mixed-model estimation.
model$set_cluster("sample", ICC = 0.30, n_clusters = 40)
# Power at N=200 for both dummy contrasts (mixed defaults: 800 sims, alpha=0.05,
# seed=2137). The omnibus test is not reported for mixed models; target the
# condition dummy coefficients directly (the bare factor name is not a test).
invisible(model$find_power(sample_size = 200, target_test = "condition[2], condition[3]"))