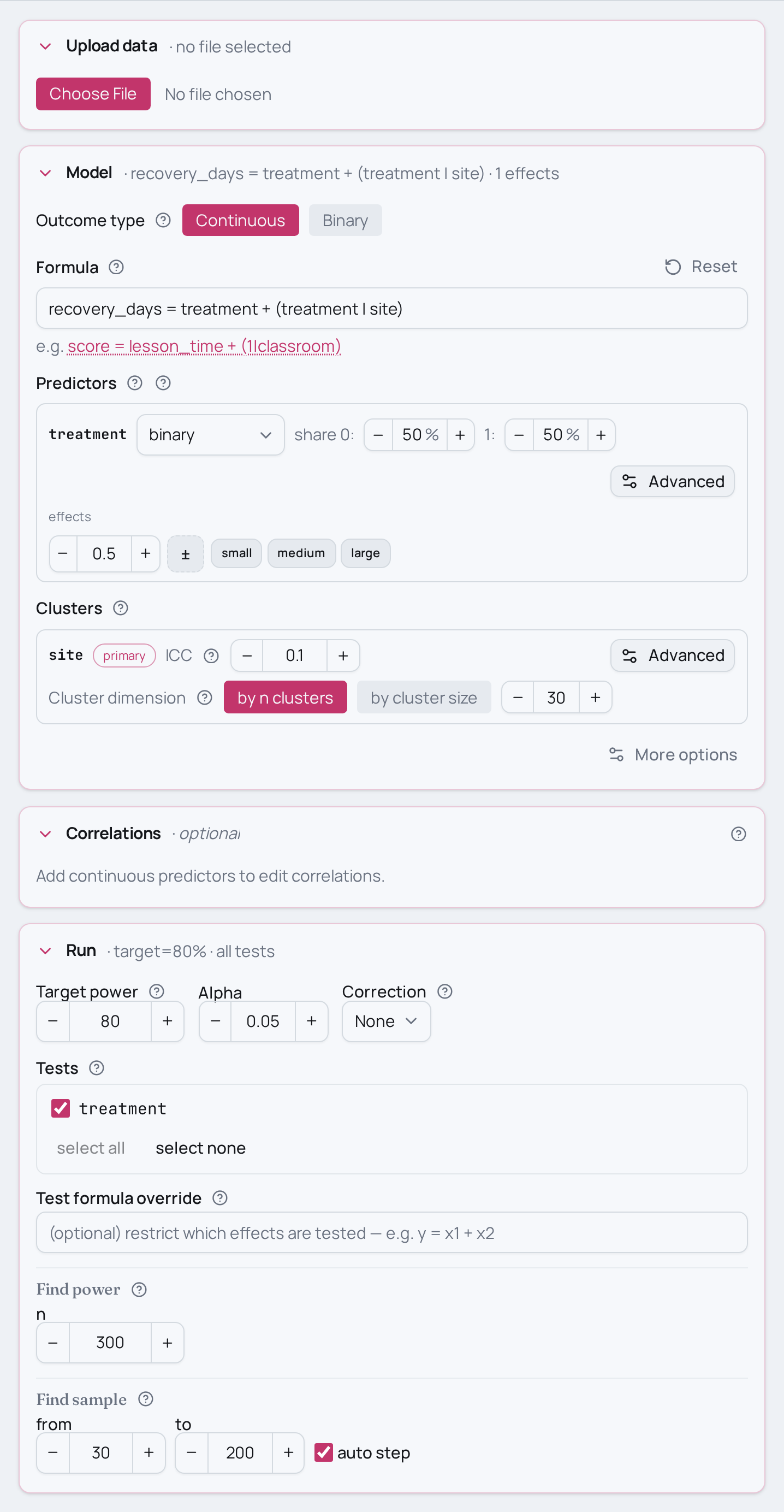
Power for a multisite trial, random slope
You ran a cluster-randomised trial across several clinical sites — whole sites were
assigned to treatment or control — and you measured recovery days on each patient.
You expect the treatment to help on average, but you also expect its effect to
differ from site to site. You fit a linear mixed model that gives each site its own
intercept and its own treatment slope:
recovery_days ~ treatment + (treatment | site).
Variations
- How much the effect swings across sites.
slope_variance=0.05controls how far each site's treatment effect strays from the average. Push it up (sites respond very differently) and power for the average effect drops — a varying effect is harder to pin down than a constant one. Set it to0.0and you are back to a random-intercept-only model. - Baseline tied to response.
slope_intercept_corr=0.0assumes a site's baseline level says nothing about how well treatment works there. Make it negative (sites that start worse recover the most) or positive (better-equipped sites gain the most) to match your domain knowledge. - Stronger or weaker clustering.
ICC=0.10says 10% of the residual variance sits between sites. Raise it towardICC=0.30if sites are very different from one another — higher ICC leaves less independent information per patient. - More sites vs more patients per site. Hold N=300 but change
n_clusters— 15 sites means 20 patients each, 50 means 6 each. For a random-slope design, adding sites usually buys far more power than adding patients to the existing ones. - Smaller or larger treatment effect.
treatment=0.50is a medium benefit on the binary benchmark scale; swap it fortreatment=0.20(small) ortreatment=0.80(large) to see how the expected effect moves power. - Solve for N instead. Replace
find_power(sample_size=300, …)withfind_sample_size(target_test="treatment", from_size=180, to_size=600, by=60)to get the minimum total sample that reaches 80% power. - Same design, other fields:
biomass ~ treatment + (treatment|habitat)— habitats randomised to restoration treatment; treatment benefit varies across habitat types (ecology).wage ~ training + (training|region)— regions randomised to a training programme; earnings gain varies across regions (social science).
Not this setup?
- Cluster-randomised trial, random intercept only — same multisite design but the treatment effect is assumed constant across sites (no random slope).
- Cluster-randomised trial with a baseline covariate — random intercept plus a baseline covariate adjustment instead of a random slope.
- Treatment moderating individual week slopes — a random-slope design in a longitudinal setting, with slopes on a within-subject variable.
If you'd rather have…
- Random intercept only — same multisite / cluster-randomised treatment design but with only a random intercept per cluster (no random treatment slope) — the simpler model when you assume the treatment effect is constant across sites.
- Add a baseline covariate — cluster-randomised treatment with a random intercept plus a baseline covariate adjustment — add covariate control instead of a random slope.
- Treatment × random week slopes — a random treatment-by-slope
structure in a longitudinal setting: treatment moderating individual random
week slopes (
fertilizer * week + (week | seedling)) — random slopes on a within-subject variable rather than across sites. - The canonical random intercept and slope — the
intercept-and-slope structure (
week | seedling) without the treatment effect — the building block for understanding random slopes.
Copy-paste setup
from mcpower import MCPower
# Multisite (cluster-randomised) clinical trial: whole sites are assigned to
# treatment or control, one continuous recovery outcome per patient. The
# (treatment | site) term gives each site its own intercept AND its own
# treatment effect — the benefit is allowed to vary from site to site.
# family="lme" fits it by maximum likelihood (MLE estimator).
model = MCPower("recovery_days = treatment + (treatment | site)", family="lme")
# Treatment is randomised at the site level, so it is a binary 0/1 predictor.
model.set_variable_type("treatment=binary")
# Expected effect on the standardised benchmark scale (binary predictor):
# treatment=0.50 -> a medium average reduction in recovery days due to treatment.
model.set_effects("treatment=0.50")
# Clustering: ICC=0.10 (10% of residual variance is between sites) across 30
# sites. random_slopes=["treatment"] turns on the random treatment slope, with
# slope_variance sizing how much the treatment effect swings across sites and
# slope_intercept_corr linking a site's baseline to its treatment response.
# treatment is constant within a site, so it is a cluster-level predictor.
model.set_cluster(
"site",
ICC=0.10,
n_clusters=30,
random_slopes=["treatment"],
slope_variance=0.05,
slope_intercept_corr=0.0,
cluster_level_vars=["treatment"],
)
# Power at N=300 for the fixed effect of treatment (mixed defaults: 800 sims,
# alpha=0.05, seed=2137). The omnibus test is not reported for mixed models;
# target the coefficient directly.
model.find_power(sample_size=300, target_test="treatment")
suppressMessages(library(mcpower))
# Multisite (cluster-randomised) clinical trial: whole sites are assigned to
# treatment or control, one continuous recovery outcome per patient. The
# (treatment | site) term gives each site its own intercept AND its own
# treatment effect — the benefit is allowed to vary from site to site.
# family = "lme" fits it by maximum likelihood (MLE estimator).
model <- MCPower$new("recovery_days ~ treatment + (treatment | site)", family = "lme")
# Treatment is randomised at the site level, so it is a binary 0/1 predictor.
model$set_variable_type("treatment=binary")
# Expected effect on the standardised benchmark scale (binary predictor):
# treatment=0.50 -> a medium average reduction in recovery days due to treatment.
model$set_effects("treatment=0.50")
# Clustering: ICC=0.10 (10% of residual variance is between sites) across 30
# sites. random_slopes carries one structured spec per slope: variance sizes how
# much the treatment effect swings across sites and corr_with_intercept links a
# site's baseline to its treatment response. treatment is constant within a site,
# so it is also a cluster-level predictor.
model$set_cluster(
"site",
ICC = 0.10,
n_clusters = 30,
random_slopes = list(
list(predictor = "treatment", variance = 0.05, corr_with_intercept = 0.0)
),
cluster_level_vars = "treatment"
)
# Power at N=300 for the fixed effect of treatment (mixed defaults: 800 sims,
# alpha=0.05, seed=2137). The omnibus test is not reported for mixed models;
# target the coefficient directly.
invisible(model$find_power(sample_size = 300, target_test = "treatment"))