Power for conditional growth curve models
You ran a randomised longitudinal plant study: each seedling is measured several
times over week, half assigned to a fertilizer arm and half to control. The
question that motivated the design is not the average growth trend, nor the baseline
group gap, but whether the two groups drift apart in growth rate as weeks go on —
the fertilizer-by-week interaction, the classic test of whether a treatment changes
the rate of growth. Because each seedling contributes a whole trajectory, you let
every seedling have its own starting height and its own growth slope, so the model
accounts for the fact that some seedlings simply grow faster regardless of arm.
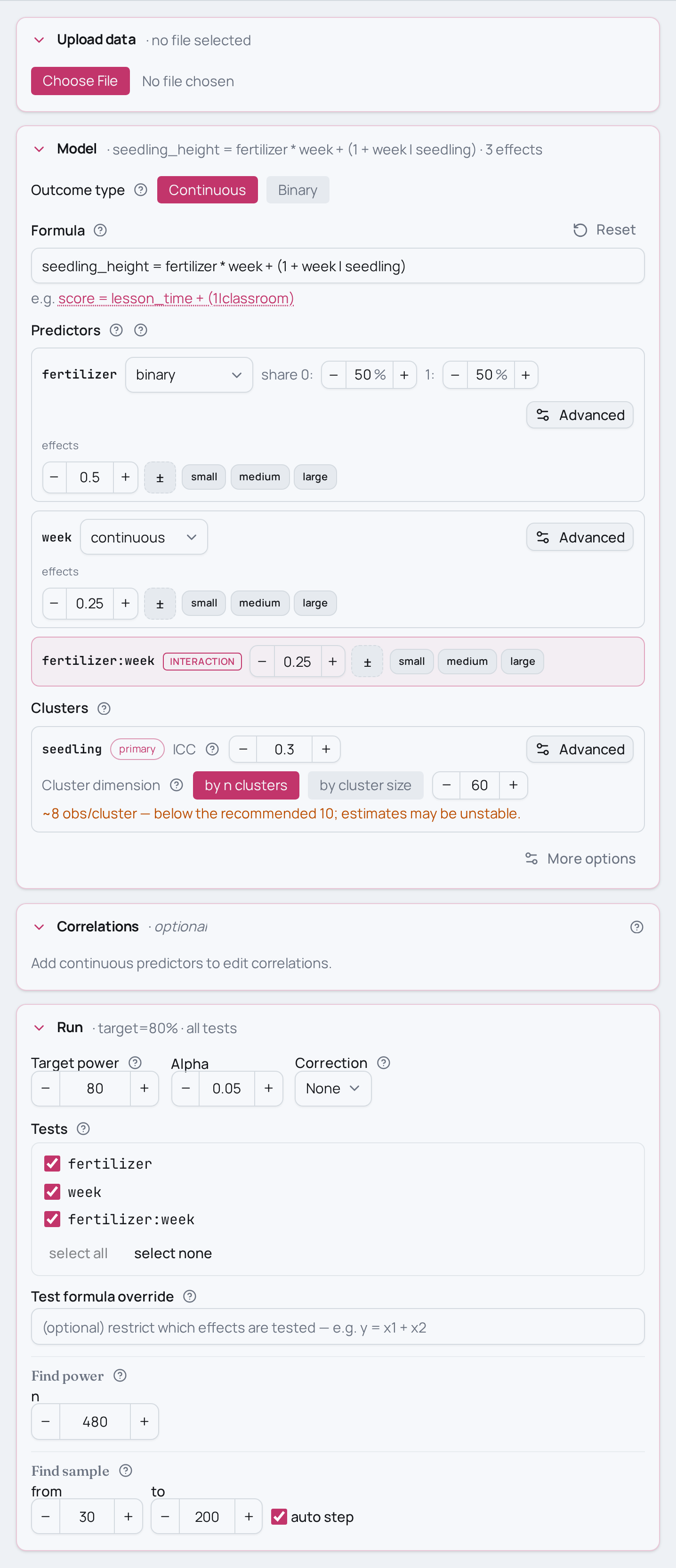
As an MCPower formula this is seedling_height = fertilizer * week + (1 + week | seedling) with family="lme", where * expands to
fertilizer + week + fertilizer:week. fertilizer is a two-level arm and week
is a continuous within-seedling measure; (1 + week | seedling) gives each
seedling a random intercept and a random slope on week. The test of interest is
the interaction fertilizer:week, fitted by a linear mixed model (the default MLE
estimator).
Variations
- Search for the N you need instead of scoring one design: swap
find_power(sample_size=480, …)forfind_sample_size(target_test="fertilizer:week", from_size=240, to_size=960, by=60). With cluster size fixed per seedling the search trades off how many seedlings you recruit; an interaction on a slope is data-hungry, so set the upper bound generously. - More or fewer measurements per seedling: the
sample_sizeis total observations, so at 60 seedlings480means 8 measurements each — raise it to lengthen the follow-up, or add seedlings by raisingn_clusters. - Weaker or stronger divergence: move
fertilizer:weekacross the continuous benchmarks — 0.10 (subtle), 0.25 (medium), 0.40 (the groups separate sharply) — to watch how fast power for the interaction collapses as the divergence shrinks. - More variable growth slopes: raise
slope_variance(or, in R, the per-slopevariance) so seedlings' week trajectories spread out more — heavier between-seedling slope variance costs power for the average divergence term. - A coarser grouping: swap the within-seedling
(week | seedling)for a random intercept only,(1 | seedling), if you are willing to assume every seedling shares one common week slope (see the link below). - Same design, other fields:
pain_score ~ treatment * week + (1 + week|patient)— one patient per arm, assessed at multiple clinical visits; test whether trajectories diverge (clinical).life_satisfaction ~ intervention * wave + (1 + wave|individual)— one person per arm, surveyed repeatedly; test whether well-being slopes differ (social science).
Not this setup?
- Linear growth curve: random intercept and slope of week
- Treatment x week interaction (two-arm longitudinal / split-plot mixed ANOVA)
- Multisite trial: treatment effect varying across sites (random treatment slope)
If you'd rather have…
- Linear growth curve: random intercept and slope of week — Unconditional linear growth (random intercept + slope of week) without a treatment moderator — the base growth-curve model before adding a between-subjects predictor of the slope.
- Treatment x week interaction (two-arm longitudinal / split-plot mixed ANOVA) — Treatment x week interaction with only a random intercept per seedling — same conditional-growth question but slopes are assumed fixed across seedlings (no random slope).
- Multisite trial: treatment effect varying across sites (random treatment slope) — A predictor with its own random slope (treatment | site) — when you want the treatment effect itself to vary randomly across clusters rather than week slopes varying across seedlings.
- Pre-post repeated measures: random intercept per patient — Simplest repeated-measures pre-post with random intercept only — the entry point before adding week slopes or a treatment moderator.
- Logistic GLMM with a continuous predictor and random slope — The binary-outcome analogue: a continuous predictor with a random slope (dose | subject) when the longitudinal outcome is a 0/1 event rather than continuous.
Copy-paste setup
from mcpower import MCPower
# A randomised longitudinal plant trial: each seedling is measured repeatedly
# over `week`, half under `fertilizer` treatment and half under control, and the
# question is whether the two groups diverge in growth rate as weeks go on —
# the fertilizer-by-week interaction. '*' expands fertilizer * week to
# fertilizer + week + fertilizer:week, so the divergence term is fitted
# explicitly. (1 + week | seedling) gives every seedling its own intercept AND
# its own week slope, so individual growth trajectories are allowed to vary.
# family="lme" makes this a linear mixed model; the default MLE estimator fits
# the variance components.
model = MCPower("seedling_height = fertilizer * week + (1 + week | seedling)", family="lme")
# fertilizer is a two-arm 0/1 factor; week is a continuous within-seedling measure.
model.set_variable_type("fertilizer=binary")
# Effect sizes on the benchmark scale.
# fertilizer=0.50 -> medium baseline group gap (binary benchmark).
# week=0.25 -> medium average within-seedling growth trend (continuous benchmark).
# fertilizer:week=0.25 -> medium divergence: the fertilized group's growth rate
# exceeds control's (the test of interest).
model.set_effects("fertilizer=0.50, week=0.25, fertilizer:week=0.25")
# Clustering by seedling: a conditional ICC of 0.3 (moderate within-seedling
# correlation), 60 seedlings, and a random slope on week whose own variance
# is modest and is mildly positively correlated with the intercept (taller
# seedlings at baseline tend to grow a little faster).
model.set_cluster(
"seedling",
ICC=0.3,
n_clusters=60,
random_slopes=["week"],
slope_variance=0.05,
slope_intercept_corr=0.3,
)
model.set_seed(2137)
# Power for the fertilizer-by-week divergence at 8 measurements per seedling.
model.find_power(sample_size=480, target_test="fertilizer:week")
suppressMessages(library(mcpower))
# A randomised longitudinal plant trial: each seedling is measured repeatedly
# over `week`, half under `fertilizer` treatment and half under control, and the
# question is whether the two groups diverge in growth rate as weeks go on —
# the fertilizer-by-week interaction. '*' expands fertilizer * week to
# fertilizer + week + fertilizer:week, so the divergence term is fitted
# explicitly. (1 + week | seedling) gives every seedling its own intercept AND
# its own week slope, so individual growth trajectories are allowed to vary.
# family = "lme" makes this a linear mixed model; the default MLE estimator fits
# the variance components.
model <- MCPower$new("seedling_height ~ fertilizer * week + (1 + week | seedling)", family = "lme")
# fertilizer is a two-arm 0/1 factor; week is a continuous within-seedling measure.
model$set_variable_type("fertilizer=binary")
# Effect sizes on the benchmark scale.
# fertilizer=0.50 -> medium baseline group gap (binary benchmark).
# week=0.25 -> medium average within-seedling growth trend (continuous benchmark).
# fertilizer:week=0.25 -> medium divergence: the fertilized group's growth rate
# exceeds control's (the test of interest).
model$set_effects("fertilizer=0.50, week=0.25, fertilizer:week=0.25")
# Clustering by seedling: a conditional ICC of 0.3 (moderate within-seedling
# correlation), 60 seedlings, and a random slope on week whose own variance
# is modest and is mildly positively correlated with the intercept (taller
# seedlings at baseline tend to grow a little faster).
model$set_cluster(
"seedling",
ICC = 0.3,
n_clusters = 60L,
random_slopes = list(
list(predictor = "week", variance = 0.05, corr_with_intercept = 0.3)
)
)
model$set_seed(2137)
# Power for the fertilizer-by-week divergence at 8 measurements per seedling.
invisible(model$find_power(sample_size = 480, target_test = "fertilizer:week"))